구글 검색엔진에서 [로봇, robots]은 구글이 웹사이트를 자동으로 검색하는 데 사용하는 프로그램을 지칭합니다. 구글 서치 콘솔을 사용하다 보면 자주 마주치는 용어인데요. 구글에서의 원활한 검색을 위하여 로봇에 대해 알아봅시다.

1. 로봇의 의미

로봇은 '크롤러', 또는 '스파이더'라고도 불리는 검색엔진 관련 용어입니다. 한 웹페이지에서 다른 웹페이지로 연결되는 링크를 따라가며 웹사이트를 자동으로 검색하는 데 사용되는 프로그램을 가리키는 용어로 구글의 기본 로봇은 Googlebot이라고 합니다. 쉽게 말해 웹페이지를 돌아다니며 콘텐츠를 확인하는 소프트웨어입니다.
2. robots.txt 란?

robots.txt 는 로봇이 해당 사이트를 액세스하고 콘텐츠를 확인할 수 있도록 URL을 알려주는 파일입니다. 쉽게 말해 로봇에게 이 웹페이지에 와서 콘텐츠를 확인하라고 표시를 해놓는 것이라고 하면 되겠네요. 구글 로봇의 원활한 작업을 지원하기 위해서는 이 robots.txt 파일이 해당 웹사이트 내에 존재해야 합니다.
3. robots.txt 테스트와 경고
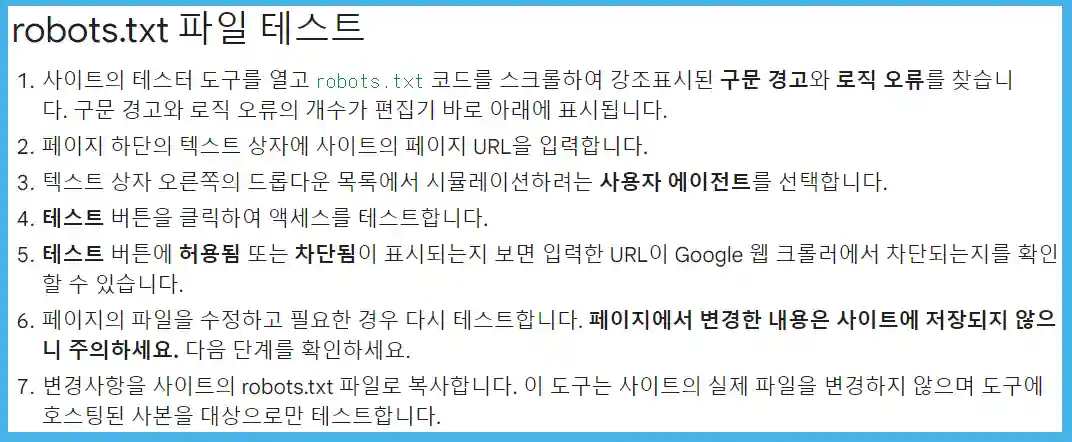
Google Search Console(이하 구글 서치 콘솔)에서는 robots.txt 테스트를 할 수 있습니다. robots.txt 파일이 특정 URL에서 구글 로봇이 검색하는 것을 방해하거나 오류를 일으키는 것이 있는지를 확인하는 테스트입니다. 이 테스트를 실행하면 Googlebot이 왔을 때 어떤 결과를 줄지 미리 확인해볼 수 있습니다.
아래의 링크를 접속해서 테스트를 진행해보시는 걸 추천드립니다.
robots.txt 테스터를 이용해 robots.txt 테스트하기 - Search Console 고객센터 (google.com)
robots.txt 테스터를 이용해 robots.txt 테스트하기 - Search Console 고객센터
robots.txt 테스터 도구는 robots.txt 파일이 사이트의 특정 URL에서 Google 웹 크롤러를 차단하는지를 알려줍니다. 예를 들어 Google 이미지 검색에서 차단하고 싶은 이미지의 URL을 Googlebot-Image 크롤러가
support.google.com
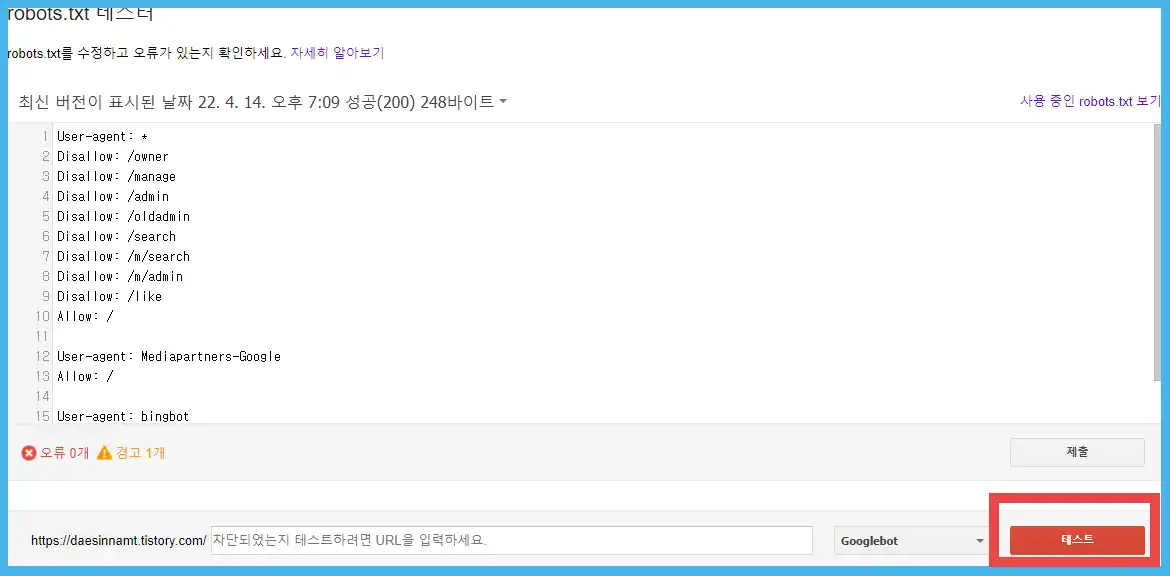
접속한 테스터에서 붉은색 네모 박스의 테스트를 클릭합니다.
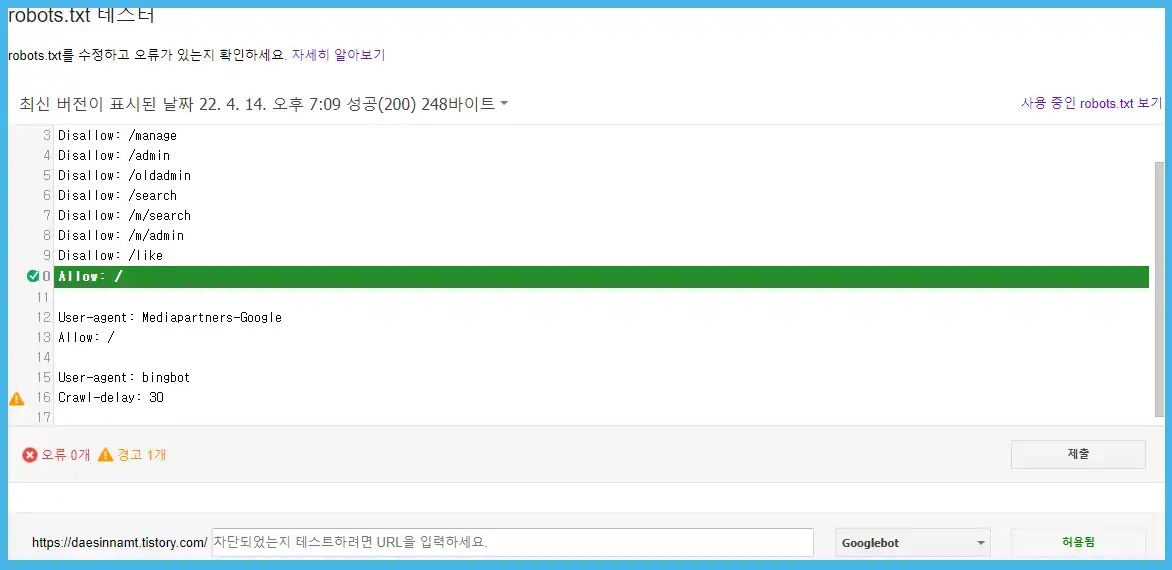
제 티스토리 블로그의 테스트 결과는 위와 같습니다. 테스트라고 적혔던 부분에 허용됨이라고 표시가 됩니다. 구글봇이 해당 robots.txt를 활용하여 테스트한 웹사이트를 방문할 수 있다는 뜻입니다. 위와 같이 결과가 나오면 티스토리 블로그의 구글 robots.txt 테스트는 통과라고 보면 되겠습니다.
여기서 노란색으로 표시된 [경고 1개] 문구를 볼 수 있는데요. 이 부분은 크게 신경 쓰지 않아도 된다고 합니다.
[ 15 User-agent : bingbot ]
[ 16 Crawl-delay : 30 ]
이 문구는 마이크로소프트 검색엔진 bing에 적용되는 내용으로 한 번의 수집 후 30초의 딜레이를 준다는 뜻입니다. 너무 많은 검색 수집으로 트래픽이 과하게 발생하는 것을 막기 위함이라고 하네요.
문과생이 티스토리와 구글 서치 콘솔을 알아가는 게 참 쉽지 않은 것 같습니다. 제가 하나씩 배워가는 과정이 다른 분들에게도 꼭 도움이 되었으면 좋겠습니다. 감사합니다.




